Details details details
April 30, 2014
I’m no fan of Metadata I can assure you. Or the method Omeka requires its users to enter it. They could at least offer an auto-fill option. According to my observations, so much of the metadata one enters for these online exhibits is repetitive. Many documents, graphs, still images etcetera a user would enter for an exhibit have at least a few of the same characteristics. Providing auto-fill is the least they could offer. I would also like to be able to edit more than one item at the same time. If all my time wasn’t being spent on entering stupid metadata I would look into sending feedback to Omeka. My exhibit contains several documents from the same source, are the same format, same description, creator, contributor etc etc. Imagine how easy it would be to enter those things all at one or with an auto-fill. Also, when adding an item, the user enters the “Dublin Core” metadata, clicks save, then we need to click edit item to add the file itself, click save, click another tab to add tags…. NOT USER FRIENDLY.
But as we continue to load files, or items, into our exhibits, we deepen our understanding of the trials and tribulations of those who lived and died during the atrocity of the grossly misnomered Civil War.
Reading vs Text Mining – a showdown
April 18, 2014
I’ll take text mining, thank you. When it comes to counting words, finding frequencies and patterns on a large scale, relying on text mining is the way to go. For studying these qualities or to research the history of the usage of words I would use a computer program like Google Ngram or Voyant to do the work for me. Corpora, which is Latin for bodies, is a similar program from Brigham Young University which seems to have information on every word ever uttered or printed. Programs such as these can summarize the text and count the unique words, the frequency of repeated words, word trends, keywords in context, provide historical information about a word, and the user can even use a provided tool which will take out so called ‘stop words’ – common usage words that have no bearing on the study of the text. Words such as and, but, as, then, with, to, etc etc are considered stop words. Also, if you so choose, some of these programs can create a word cloud to turn the results of your text mining into a visual tool that brings an aesthetic value to the search. Like this: BUT if I am looking for comprehension of the document, or context or meaning, I will need to read it myself, because computers cannot read.
BUT if I am looking for comprehension of the document, or context or meaning, I will need to read it myself, because computers cannot read.
I have been trying to determine a use for this sort of service which is applicable to our project but can not really recognize one. I don’t think mining any of the documents I have found which directly affect my soldier would provide any significant information on who he was as a person.
I really enjoy the word cloud features of these programs and I can think of lots of uses for that. Here is one from a page of my website: 
Digital Mapping (your FACE!)
April 14, 2014
There are many reasons digital mapping supersedes the benefits of traditional maps, the primary being the ability to update. Back in the olden days, a paper map could only be updated by setting the old one on fire and printing out a new one complete with new information. As Earth’s population spreads across the globe, maps need constant updating to meet the needs of new streets, communities and populace. Digital maps also offer the ability to generate layers to a map. Be they historical layers, terrain, weather related, or traffic, layering and customizing a digital map to meet the user’s needs is incomparable to traditional methods. The user has the option to look at all or any combination of these layers based on the research they are doing. Also, multiple users are able to access and alter the same online document simultaneously which is another tremendous benefit.
By using digital mapping in our soldier projects, we can further illustrate the scope of their lives: where they were born, lived, raised families, and where they died. Seeing where these events happened on a map, as opposed to simply reading about it, works to deepen our vision of how they lived and died.
As Trevor Harris, Jesse Rouse and Susan Bergeron argue, “The visual display of information creates a visceral connection to the content that goes beyond what is possible through traditional text documents.”
Trevor Harris, Jesse Rouse and Susan Bergeron, “The Geospatial Semantic Web, Pareto GIS, and the Humanities,” in The Spatial Humanities: GIS and the Future of Humanities Scholarship, ed. David Bodenhamer, John Corrigan and Trevor Harris (Bloomington: Indiana University Press, 2010), 124-142
My thoughts on Daytum
April 9, 2014
We were tasked with tracking specific data over the weekend, starting Thursday morning through Sunday night. The class chose CLOTHING, BEVERAGES, and PEOPLE as items to track. I wanted to suggest we each pick a fourth category of our choice but the discussion was closed after 3catagories and I was not about to suggest more work for the class. I elected to track a 4th category on my own, that being DIAPER CHANGES. My son Sawyer had been, at last class, home for just under 36 hours after having lived his first 85 days of life in the neonatal intensive care unit. Things were going as well as can be expected for two new parents and I thought it would be interesting to keep note of what comes out of my kid. Turns out that since he was dealing with some constipation, the information recorded was not all that interesting, but it was fun nonetheless.
Having already explored DAYTUM.com (click for my page) prior to class and ready to dive in, I began my information tracking on my late night baby-shift that night after class instead of the next morning. My first entry was at 3:01am and I don’t need to get into the specifics but all told that category ended up being rather uneventful.
Tracking BEVERAGES I started out using a per ounce standard of notation but then I changed it because, and here’s my big grief with Daytum, the iphone app sucks. It is not intuitive to navigate for the average user, it crashes every time I wanted to adjust the time on an entry, and there are too many different clicks to add value for one item. Why can’t I enter a value on several items all at once and then click save all? It also took me forever to figure out where to swipe after entering a value just to leave that page.
The full website had its share of problems as well. Namely, several times when I wanted to adjust the settings, and hence clicked on that tab, I would get an error message of Problem Loading That Page. I really like the monochromatic theme of the website however, especially in regards to the charting and graphing. The Pie graph for my PEOPLE category is quite lovely as a result. 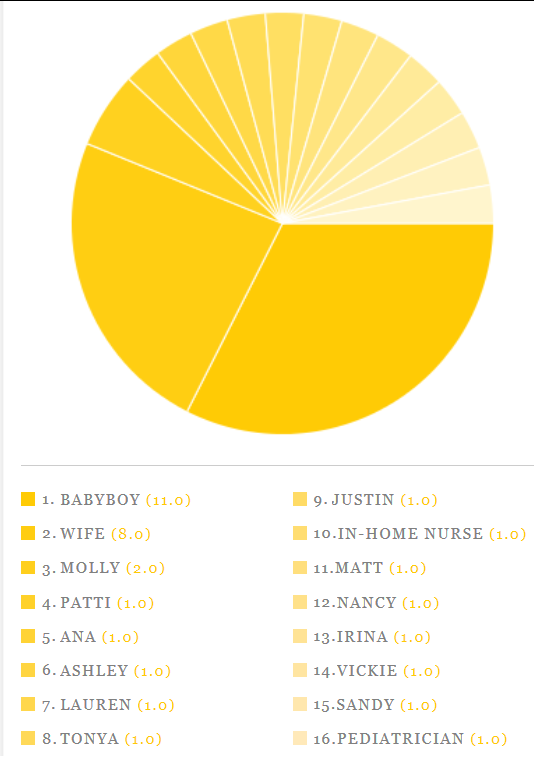
Since my wife’s maternity leave from work was depleted while Sawyer was in the NICU, I am his principal caretaker during the daytime. (As a result, this review of Daytum is completed in fits and starts, coinciding with those of the baby, over the course of several hours). I was really hoping the app would be more accommodating in documenting the data I wished to track but it ended up being more hindering than helpful.
I can see using this site again. It certainly was interesting and enlightening to look back on the information chronicled, and this was a fun exercise.
Notes on DATABASEs
March 31, 2014
From Wikipedia – A database is an organized collection of data. The data are typically organized to model relevant aspects of reality in a way that supports processes requiring this information. For example, modeling the availability of rooms in hotels in a way that supports finding a hotel with vacancies.
Harvey and Press provide a definition – “A database is a collection of inter-related data organised in a pre-determined manner according to a set of logical rules, and is structured to reflect the natural relationships of the data and the uses to which they will be put, rather than reflecting the demands of the hardware and software.”
From Databases for Historians, Designing Databases for Historical Research by Mark Merry
The historian is faced with particular kinds of problem when it comes to converting sources into a useful database resource, problems which are not shared by most other database users. This (as we shall see) boils down to two separate inescapable realities of historical research:
- The historian often does not know precisely what kinds of analyses they want to conduct when starting out on their research
- The extent and scope of the information contained within the historian’s particular sources cannot usually be anticipated fully
- and I will add: the historian does not quite know how to fit traditional historical documents into digitized files that will be comprehensibly put together into a cohesive thematic online structure. (wow that was pretty good!)
Databases have very strict rules about what type of information goes where, how it is represented and what can be done with it and if the information from our sources can be made to obey these rules then it has become data.
One of the database rules alluded to above is that all data in the database sit in tables, regardless of what kind of data they are.
There are four main elements to any table in a database, and each of these have (somewhat inevitably) a number of names:
§ Table (also known as Entities)
§ Field (also variously known as Column, Variable, Attribute)
§ Record (also known as Row)
§ Field name (also known as the Attribute name)
Database Rules referred to by Harvey and Press
- The ‘information rule’: all information in a relational database is represented in one way – as a value in a field in a table.
- Each table in a relational database will have a name which uniquely identifies it and which will distinguish it from the other tables; the table should contain information about only one entity.
- Each field within a table is given a unique name within the table.
- The values in each field must have the same logical properties, that is, must be of the same datatype: numerical or text.
- Records will contain closely related information about a single instance of the entity (that is, the subject of the table – for example, the forename and surname of a single individual in a table about individuals).
- The order of records in a table must not be significant.
- The order of fields in a table must not be significant.
- Each complete record must be unique.
- Each field should contain ‘atomic values’: this is, indivisible data (e.g. first and last names of an individual should always be held in separate fields).
Datatypes
Each field within a database must be of a certain datatype. In essence what datatypes do is to control what type of data is entered into a field. Each field in each table is assigned a datatype, usually ‘text’ or ‘numeric’, and this in turn dictates what kind of data can be entered into that field. Every field in every table will need to have one of these datatypes assigned.
The basic datatypes: text
- This is the default datatype for your fields which will be assigned by the database whenever you add a new field to a table
- This datatype will allow the entry of textual and numerical values, although it will treat that latter differently from numerical values entered into a ‘number’ datatype field
The basic datatypes: memo
- Fields with this datatype are used for lengthy texts and combinations of text and numbers
- Data in these types of field cannot be sorted and difficult, although not impossible, to query
The basic datatypes: number
- This datatype allows the entry of numerical data that can be used in arithmetical calculations
- There are a number of variations of this datatype
The basic datatypes: date/time
- This datatype can be customised in order to control the format of dates that are entered
- This datatype will allow the sorting of records chronologically
The basic datatypes: currency
- This datatype allows the entry of numerical values data used in mathematical calculations involving data with one to four decimal places, with the inclusion of currency symbols
The basic datatypes: autonumber
- This datatype automatically generates a unique sequential or random value whenever a new record is added to a table.
- AutoNumber fields cannot be updated, that is, you cannot enter data into them manually
The basic datatypes: yes/no
- A field with this type of datatype will only contain one of two values (Yes/No, True/False, or On/Off)
- Quite often database software will represent this type of field as a checkbox in the table
The basic datatypes: OLE
- A field with this datatype is one in which another file is embedded, as a Microsoft Excel spreadsheet, a Microsoft Word document, an image, a sound or video file, an html link, or indeed any other type of file
Printing Wikipedia
March 30, 2014
Very interesting radio report from National Public Radio regarding printing the entire Wikipedia site.
http://www.npr.org/blogs/alltechconsidered/2014/03/27/295262783/printing-wikipedia-would-take-1-million-pages-but-thats-sort-of-the-point
M E T A D A T A is data, about data.
March 28, 2014
Continuing our pursuit of the unknown, we dive deep into the digital history of the soldiers of the Civil War. And in order to make the research easier, we, like many previous online historians will provide searchable key words and information to link our findings to the researchers of the future. This is called METADATA. METADATA is also the trail of information left behind after any digital transaction, for example when you send an email, a LOOOOOONG trail of information is left behind….
- sender’s name, email and IP address
- recipient’s name and email address
- server transfer information
- date, time and timezone
- unique identifier of email and related emails
- content type and encoding
- mail client login records with IP address
- mail client header formats
- priority and categories
- subject of email
- status of the email
- read receipt request
Or when you use your camera-phone…..
- photographer identification
- creation and modification date and time
- location where photo was taken
- details about a photo’s contents
- copyright information
(These examples provided by The Guardian)
For our purposes, we will enter METADATA information about our soldiers so that future researchers can find what we have digitized and compiled.
I entered a few more documents into my OMEKA project site. I thought it important to add George Karn’s original volunteer enlistment form but Google was unable to OCR anything more from the document than “VOLUNTEER ENLISTMENT,” so I transposed the entire document myself. It took a while but I think it was worth the time.
As far as what the NSA is doing with our METADATA, I think it’s wasted energy to complain about it. We live in an age where privacy is no longer an assured privilege to each member of society. Some people have less privacy than others and some people have nearly none at all, some by choice, some by profession. To tell the government they are not allowed to collect data of any kind on it’s citizens or on citizens of other countries is a futile effort in my opinion. The government will do it one way or another, and if they don’t they will be at a great disadvantage to those entities that do. And a LOT has happened since this article was written in July of 2013.
Diving deep into George Karn
March 27, 2014
My father LOVES this sort of research so I have been consulting his expertise as we have proceeded through this exercise. My dad has spent hours upon hours researching our family history and has quite an extensive narrative to show for his efforts. He has acquired many primary sources such as letters, diaries and sheet music written by our forefathers to compliment his online history of my family. His work is an excellent template for digitizing a family history. Hopefully one day my son, and his son, and his son, and his son will appreciate all the hours of work he has put into it as much as I do. He has assisted my efforts during this process and been of vital help finding more sources for my project. I hope this is in no way antithetic to the Honor Code, but since he is simply offering advice and directing me towards further information online I do not think it would be. He wishes he lived closer so he could take this class with me!
Entering all the information into my Soldier Summary spreadsheet required a LOT of squinting. I guess I am at that age where I might need glasses. Back and forth and back and forth between the photos of the docs and the spreadsheet. Once I got into the groove of the process it became a little easier. Once I turned to my online sources this process became even easier.
My soldier, George Karn, spent almost half of his life trying to bust the bureaucracy of the federal government in pursuit of his due pension. He enlisted at age 15, dubiously conscripting the help of an older friend to vouch for his stated age of 18 at the time. Mr. Karn could not read or write when he joined and signed his papers with an X. But curiously enough, learned both skills during his service in the military. He never married, and never lived any farther than 100 miles of where he was born. George Karn died at age 61 at a home for disabled veterans in Milwaukee, Wisconsin. The cause of death was listed as myocarditis and acute alcoholism.
The story unfolds….
What is a BROWSER?
March 18, 2014
Watch this cool video to find out.
Psssssst!! Whats the password?
March 7, 2014
12356Pa$$wor[)
How’s that one? Nope the nefarious bastards that spend all their time and talent being criminal can crack that. They figured out algorithms to crack passwords with
- real details? My mom’s maiden name is Flubbywacker and the street I grew up on is now Snoobdrow Street.
- Capitals at front? nOt anYmorE
- numbers/punctuation at end? %%BaD11idea++
- first name & date? I’ll use my son’s name and birthdate as a password, Kracklebutt13.32.2014 – perfect.
- mangling with number3 and $ymbols? th3y’11 figur3 1t 0ut 3v3ryt1m3
My passwords got more complex when I met my wife because she insisted on it. I was a capitalize first letter-word from dictionary-end with a number type of guy until I met her.
She also insisted on backing up our computers on a regular basis and I admit that was something I had never even heard of.
One frustration we have now is how spread out our photos are. First there was Ofoto, then it changed to kodakgallery, then she had picasa, but I didn’t like it so we tried snapfish then shutterfly….not to mention all the ones that never made it online that are in 2 different computers now. Ugh. That’s a project we need to catch up on sometime.
I do have a few old emails saved. Interesting stuff that I think I will draw from in the future or just enjoy revisiting. I have had the same email address since 1999. Unfortunately hotmail used to have a very limited amount of available space you were allotted so I had to dump stuff a long time ago. The oldest email I have is from 2002. I’ll cherish it as a badge of honor. My dad is a great writer so I have several emails from him that I used to print out and keep in a book but once hotmail grew I was able to just save them in there.
I am worried about this mid-term! I don’t test well. That explains why I’m a theater performance major instead of something more…..practical? I find our subject matter very interesting but can I relate the information back when needed? We shall see!
Assess your backup and preservation practices. Aids to preservation – you need documentation of how something works, otherwise it will be pretty hard to fix it later. Standards, metadata = where things come from, makes your information usable.
best practice 3-2-1
3 copies in 2 formats in 1 place other than home.
What should be archived?
What are the challenges of preserving born digital records? What do you save, what do you discard? Why is one thing more important than something else? Who are you to decide what future seekers of information might need or not need? Should we just save everything?? Will there someday be a show called Digital Hoarders?
Passwords fail because
- guessed
- lifted from password dump – reusing from multiple sites
- cracked by brute force
- hashed values – a result of a calculation (hash algorithm) that can be performed on a string of text, electronic file or entire hard drives contents
- rainbow tables – a precomputed table for reversing cryptographic hash functions, usually for cracking password hashes
- salting – random data that is used as an additional input to a one-way function that hashes a password or passphrase. The primary function of salts is to defend against dictionary attacks and pre-computed rainbow table attacks.
- stolen by keylogger/malware
- reset by customer support
I have no idea what the terms in orange mean.